UPDATE
The quick guide on setting the FPU ON on STM32F407 boards under STM32duino
Will be precised further on
FPU on STM32F4xx is a Single Precision Floating Point Unit. It will not work for double precision math acceleration.
The size is 32bit with this FPU. The expected precision is ~7 digits with basic math primitives and typical algorithms. With transcendental math functions do expect 5-6 digits.
The Single Precision theoretical scope is from +/- 1.175494351E-38 .. 3.402823466E+38.
Not all real numbers have their Single Precision representation, though.
The FPU provides only a few basic primitive functions (like add, sub, mul, div, sqrt) and several other supporting functions. It does not provide you with results like sinf(), still the sw math libraries must be used for transcendental functions. With stm32duino the gcc build-in libraries will be used (when proper compile flags are used). You may also use CMSIS DSP library instead.
[attachment=1]STM32F407 FPU INSTR.JPG[/attachment]
The Single Precision is good for:
1. audio, video, sensors processing, control and regulation – everywhere you need speed, large dynamics, but lower resolution is acceptable
2. for DSP with 12-18bit ADC values, FFT, IFFT, FIR IIR filters, SI conversions
3. math with and printing out real values with larger order ranges (pico, nano,.., mega, giga) but with 6-7 digits
4. math calcs where the algorithm can accept the lower resolution.
The Single Precision is NOT good for:
1. navigation, gps, cartography, land surveying
2. measuring and calcs with frequencies (DDS, frequency measurements, etc.)
3. numerical calculation in science and technology – in mathematics, physics, astronomy, etc.
4. pocket calculators
5. CAD systems and simulators
6. financial calculation.
HINT: I recommend this reading https://ece.uwaterloo.ca/~dwharder/Nume … /paper.pdf
as the using of floating point math could be sometimes tricky..
In your platform.txt add
-mfloat-abi=hard -mfpu=fpv4-sp-d16 -fsingle-precision-constant
for now i’ve not found any marcos or defines as related to -mfloat-abi=hard etc
it would seem that hardware float would need to be handled as somewhat a ‘library’ approach. i’d think the missing CMSIS libmath.a libraries probably is a reason causing my sketch to ‘hang’. the surprising thing would be that with gcc 6 i didn’t seem to hit compile or link errors that functions are missing
Running:
arm-none-eabi-gcc -mcpu=cortex-m4 -mthumb -mfloat-abi=hard -mfpu=fpv4-sp-d16 -E -dM - < /dev/null
vpadd.u<illegal width 64>http://infocenter.arm.com/help/topic/co … BJHIG.html
//enable the fpu (cortex-m4 - stm32f4* and above)
void enablefpu()
{
__asm volatile
(
" ldr.w r0, =0xE000ED88 \n" /* The FPU enable bits are in the CPACR. */
" ldr r1, [r0] \n" /* read CAPCR */
" orr r1, r1, #( 0xf << 20 )\n" /* Set bits 20-23 to enable CP10 and CP11 coprocessors */
" str r1, [r0] \n" /* Write back the modified value to the CPACR */
" dsb \n" /* wait for store to complete */
" isb" /* reset pipeline now the FPU is enabled */
);
}
-mfloat-abi=softfp -mfpu=fpv4-sp-d16it is discussed somewhere in boinc (mass distributed community computing projects) forums
if you have a statement c = a + b, and c is not referenced anywhere. gcc could *remove* it, and that happens with whetstone codes (perhaps with the -O3 optimization), if gcc get even ‘smarter’ and remove all the whetstone codes because it is ‘doing nothing’ performance tends to infinity, faster than the fastest supercomputer in the world petaflops in 0 nanooseconds ![]()
p.s. what the boinc people did is they assign the whetstone results to global variables, so that gcc won’t remove it, but we’d leave that ‘enhancement’ for another time
I will try with -O0 as the last exercise today..
EDIT: The 65MIPS most probably a fizzle..
Loops: 1000Iterations: 10Duration: 23948 millisec.
C Converted Single Precision Whetstones: 41.76 MIPSusage:
connect to usb-serial console, press ‘g’ to start
– v0.5 fixes for single precision, call single precision math lib functions instead of double precision functions
added codes to detect if software floating point or hardware floating point is selected
– v0.4 added fpu enabling codes
– v0.3 fixed a dangling double makes single precision work longer than expected
– v0.2 fixed some syntax errors
– v0.1 initial release
stm32f407vet
compiled optimization -O0 no optimization, no debug
hardware floating point, single precision
Beginning Whetstone benchmark at 168 MHz ...
Loops:1000, Iterations:1, Duration:2486.45 millisec
C Converted Single Precision Whetstones:40.22 mflops
Here is a benchmark I used to use in past. It computes integrals of various crazy funcions. Comes from Rosetta code, but I changed the functions (it compares numerical integration methods and analytical integration results of the respective functions).
We may use it as a benchmark for single and double experiments. I can hardly imagine it optimizes something off ![]()
Just add time measurement and that is. It is much better benchmark as the Whetstone dinosaur ![]()
// A Benchmark - Integrals - Single Precision (with FPU on/off)
// Based on http://rosettacode.org/wiki/Numerical_integration
// Pito 4/2014
// Mod for STM32duino 4/2017
// Functions F: f1a = INTEGRAL(f1), etc.
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <stdarg.h>
#define WITH_FPU 1
void prntf(char *fmt, ... ){
char buf[128]; // resulting string limited to 128 chars
va_list args;
va_start (args, fmt );
vsnprintf(buf, 128, fmt, args);
va_end (args);
Serial.print(buf);
}
// Integration methods
//
float int_leftrect(float from, float to, int n, float (*func)(float))
{
float h = (to-from)/n;
float sum = 0.0, x;
for(x=from; x <= (to-h); x += h)
sum += func(x);
return h*sum;
}
float int_rightrect(float from, float to, int n, float (*func)(float))
{
float h = (to-from)/n;
float sum = 0.0, x;
for(x=from; x <= (to-h); x += h)
sum += func(x+h);
return h*sum;
}
float int_midrect(float from, float to, int n, float (*func)(float))
{
float h = (to-from)/n;
float sum = 0.0, x;
for(x=from; x <= (to-h); x += h)
sum += func(x+h/2.0);
return h*sum;
}
float int_trapezium(float from, float to, int n, float (*func)(float))
{
float h = (to - from) / n;
float sum = func(from) + func(to);
int i;
for(i = 1;i < n;i++)
sum += 2.0*func(from + i * h);
return h * sum / 2.0;
}
float int_simpson(float from, float to, int n, float (*func)(float))
{
float h = (to - from) / n;
float sum1 = 0.0;
float sum2 = 0.0;
int i;
float x;
for(i = 0;i < n;i++)
sum1 += func(from + h * i + h / 2.0);
for(i = 1;i < n;i++)
sum2 += func(from + h * i);
return h / 6.0 * (func(from) + func(to) + 4.0 * sum1 + 2.0 * sum2);
}
/* test functions */
// F1
float f1(float x)
{
return ( x*x /( (-1.0 + powf(x,4.0)) * (-1.0 + powf(x,4.0)) ) );
}
float f1a(float x)
{
return ( ( (-4.0 * x*x*x)/(-1.0 + x*x*x*x) - 2.0*atanf(x) - logf(-1.0 + x) + logf(1.0 + x))/16.0 );
}
// F2
float f2(float x)
{
return ( sinf(x + 1.0)*cosf(x - 1.0)/tanf(x - 1.0) );
}
float f2a(float x)
{
return ( ( 2.0*x*cosf(2.0) + 4.0*logf(sinf(1.0 - x))*sinf(2.0) + sinf(2.0*x) )/4.0 ) ;
}
// F3
float f3(float x)
{
return ( (5.0 + 3.0*x)/(1.0 - x - x*x + x*x*x) );
}
float f3a(float x)
{
return ( -4.0/(-1.0 + x) - logf(-1.0 + x)/2.0 + logf(1.0 + x)/2.0 ) ;
}
// F4
float f4(float x)
{
return ( 1.0 /(2.0 + x*x*x*x) );
}
float f4a(float x)
{
float k = 2.0;
float m = 0.25;
return ( (-k*atanf(1.0 - powf(k,m)*x) + k*atanf(1.0 + \
powf(k,m)*x) - logf(k - k*powf(k,m)*x + sqrtf(k)*x*x) + \
logf(k + k*powf(k,m)*x + sqrtf(k)*x*x))/(8.0*powf(k,m)) ) ;
}
typedef float (*pfunc)(float, float, int , float (*)(float));
typedef float (*rfunc)(float);
#define INTG(F,A,B) (F((B))-F((A)))
void setup ()
{
int i, j;
float ic, tmp;
if(WITH_FPU) {
__asm volatile
(
" ldr.w r0, =0xE000ED88 \n" /* The FPU enable bits are in the CPACR. */
" ldr r1, [r0] \n" /* read CAPCR */
" \n"
" orr r1, r1, #( 0xf << 20 ) \n" /* Enable CP10 and CP11 coprocessors, then save back. */
" str r1, [r0] \n"
" dsb \n"
" isb" /* reset the pipeline, now the FPU is enabled */
);
}
Serial.begin(115200);
// while(!Serial.isConnected());
pfunc f[5] = {
int_leftrect, int_rightrect,
int_midrect, int_trapezium,
int_simpson
};
const char *names[5] = {
"leftrect", "rightrect", "midrect",
"trapezium", "simpson"
};
rfunc rf[] = { f1, f2, f3, f4 };
rfunc If[] = { f1a, f2a, f3a, f4a };
float ivals[] = {
2.0, 10.0,
-1.0, -0.7,
10.0, 50.0,
0.0, 10.0
};
int approx[] = { 10000, 10000, 10000, 10000 };
prntf("\nBenchmark starts..\n");
uint32 elapsed = millis();
for(j=0; j < (sizeof(rf) / sizeof(rfunc)); j++)
{
for(i=0; i < 5 ; i++)
{
ic = (*f[i])(ivals[2*j], ivals[2*j+1], approx[j], rf[j]);
tmp = INTG((*If[j]), ivals[2*j], ivals[2*j+1]);
prntf("%10s [%1.1e %1.1e] num: %1.6e, ana: %1.6e\n",
names[i], ivals[2*j], ivals[2*j+1], ic, tmp);
}
prntf("\n");
}
elapsed = millis() - elapsed;
prntf("Benchmark ends, elapsed %d msecs\n", elapsed);
}
void loop() {}
for whetstone, to prevent gcc from optimizing away codes, i’ve seen some examples such as using global variables or arrays to store the results of the whetstone computation
an example of that is in the boinc project, where whetstone benchmark is used to compute ‘credits’ for the participants as an estimate of the ‘work’ done
https://github.com/BOINC/boinc/blob/mas … tstone.cpp
the boinc codes patched the results of the calculations into global variables and arrays during the calculations so that gcc -O options would not remove them
in the mean time i’d guess we’d make do and let gcc ‘cheat’ a little & get higher m/gflops ![]()
ok signing of for the day/night
stm32f407vet
compiled optimization -O0 no optimization, no debug
hardware floating point, single precision
Beginning Whetstone benchmark at 168 MHz ...
Loops:1000, Iterations:1, Duration:2486.45 millisec
C Converted Single Precision Whetstones:40.22 mflops
stm32f407vet
compiled optimization -O0 no optimization, no debug, -fsingle-precision-constant
hardware floating point, single precision
Loops:1000, Iterations:1, Duration:2030.42 millisec
C Converted Single Precision Whetstones:49.25 mflops
i’m thinking that the -O2 and -O3 optimizations likely removed some codes, but nevertheless it is just fun to watch those ‘impossible’ mflops
Have you heard about the new Cray super computer? It’s so fast, it executes an infinite loop in 6 seconds.
![]()
Loops: 1000Iterations: 10Duration: 19638 millisec.
C Converted Single Precision Whetstones: 50.92 MIPSI can build it, but it does not run here. No idea why.. Maybe math libraries missing?? But it builds w/o error.
Can you try to run it in your environment, plz?
stm32f4vet WITH_FPU 0, optimization -Os (optimise size), debug off,v6.3.1-2017-q1-update
software floating point, single precision
Benchmark starts..
leftrect [2.0e+00 1.0e+01] num: 6.720000e-03, ana: 6.712139e-03
rightrect [2.0e+00 1.0e+01] num: 6.705779e-03, ana: 6.712139e-03
midrect [2.0e+00 1.0e+01] num: 6.712879e-03, ana: 6.712139e-03
trapezium [2.0e+00 1.0e+01] num: 6.712058e-03, ana: 6.712139e-03
simpson [2.0e+00 1.0e+01] num: 6.712050e-03, ana: 6.712139e-03
leftrect [-1.0e+00 -7.0e-01] num: -2.613795e-03, ana: -2.612248e-03
rightrect [-1.0e+00 -7.0e-01] num: -2.613944e-03, ana: -2.612248e-03
midrect [-1.0e+00 -7.0e-01] num: -2.613870e-03, ana: -2.612248e-03
trapezium [-1.0e+00 -7.0e-01] num: -2.612268e-03, ana: -2.612248e-03
simpson [-1.0e+00 -7.0e-01] num: -2.612271e-03, ana: -2.612248e-03
leftrect [1.0e+01 5.0e+01] num: 2.825554e-01, ana: 2.824790e-01
rightrect [1.0e+01 5.0e+01] num: 2.824033e-01, ana: 2.824790e-01
midrect [1.0e+01 5.0e+01] num: 2.824792e-01, ana: 2.824790e-01
trapezium [1.0e+01 5.0e+01] num: 2.824792e-01, ana: 2.824790e-01
simpson [1.0e+01 5.0e+01] num: 2.824791e-01, ana: 2.824790e-01
leftrect [0.0e+00 1.0e+01] num: 6.603576e-01, ana: 6.601052e-01
rightrect [0.0e+00 1.0e+01] num: 6.598577e-01, ana: 6.601052e-01
midrect [0.0e+00 1.0e+01] num: 6.601063e-01, ana: 6.601052e-01
trapezium [0.0e+00 1.0e+01] num: 6.601086e-01, ana: 6.601052e-01
simpson [0.0e+00 1.0e+01] num: 6.601073e-01, ana: 6.601052e-01
Benchmark ends, elapsed 8161 msecs
1. the .bin for MMini, -Os, DP, noFPU is 47.8kB
2. the .bin for 407, -O0, FPU -hard, SP is 33kB
That’s weird.. Why Whetstone compiles and runs. The same math.h, almost the same math funcs (sin/cos…).
1. the .bin for MMini, -Os, DP, noFPU is 47.8kB
2. the .bin for 407, -O0, SP is 33kB
That’s weird.. Why Whetstone compiles and runs. The same math.h, almost the same math funcs (sin/cos…).
The problem seems to be different:
1. I commented out all math in functions and return wit 1.0 – no go with FPU on, and then
2. I replaced prtn results with simple Serial.println(“Hello”) – no go with FPU on, and then
3. I replaced “float” with “double” and the FPU is on – it runs and prints Hello.
The Whetstone runs with “float” and FPU on, and with the same config (includes, asm) as here (and with the same math functions, except powf() I commented out here).
So my suspicion points to these “float” pointers exercises while FPU is on, like:
typedef float (*pfunc)(float, float, int , float (*)(float));
typedef float (*rfunc)(float);
typedef float (*pfunc)(float, float, int , float (*)(float));
typedef float (*rfunc)(float);
#define INTG(F,A,B) (F((B))-F((A)))
static pfunc f[5] = {
int_leftrect, int_rightrect,
int_midrect, int_trapezium,
int_simpson
};
static rfunc rf[4] = { f1, f2, f3, f4 };
static rfunc If[4] = { f1a, f2a, f3a, f4a };
static const char *names[5] = {
"leftrect", "rightrect", "midrect",
"trapezium", "simpson"
};
/* STM32 ISR weak declarations */
.thumb
/* Default handler for all non-overridden interrupts and exceptions */
.globl __default_handler
.type __default_handler, %function
__default_handler:
b . <<<<<< cursor
.weak __exc_nmi
.globl __exc_nmi
.set __exc_nmi, __default_handler
.weak __exc_hardfault
.globl __exc_hardfault
.set __exc_hardfault, __default_handler
.weak __exc_memmanage
.globl __exc_memmanage
.set __exc_memmanage, __default_handler
.weak __exc_busfault
.globl __exc_busfault
.set __exc_busfault, __default_handler
.weak __exc_usagefault
.globl __exc_usagefault
.set __exc_usagefault, __default_handler
.weak __stm32reservedexception7
.globl __stm32reservedexception7
.set __stm32reservedexception7, __default_handler
.weak __stm32reservedexception8
.globl __stm32reservedexception8
.set __stm32reservedexception8, __default_handler
.weak __stm32reservedexception9
.globl __stm32reservedexception9
.set __stm32reservedexception9, __default_handler
-fno-exceptions
-fno-rtti
-fno-use-cxa-atexit
-fno-threadsafe-statics
PS: the closest instruction to the exception was (before the exception)
vpush (d8,d9)
i think it probably has nothing to do with those fpu_enable codes, as i’ve enable_fpu parts of the code run after my key press, but in the first place, it did not even get into setup() as my led did not light up. hence, my guess is we’d need to patch that ISR (interrupt service routine) or something perhaps to put
void exception_handler(void) {}
or something, that’s probably very early in the ‘pre main’ parts of codes
it sounds like an interrupt fired, and there is no handler there, and not sure what is that interrupt (division by zero?), yup and i think it has something to do with init() ![]()
i think it probably has nothing to do with those fpu_enable codes, as i’ve enable_fpu parts of the code run after my key press, but in the first place, it did not even get into setup() as my led did not light up. hence, my guess is we’d need to patch that ISR (interrupt service routine) or something perhaps to put
void exception_handler(void) {}
or something, that’s probably very early in the ‘pre main’ parts of codes
it sounds like an interrupt fired, and there is no handler there, and not sure what is that interrupt (division by zero?), yup and i think it has something to do with init() ![]()
while looking at
– STM32F4/variants/black_f407vet6/stm32_vector_table.S
.long __irq_FPU_IRQHandler /* FPU */
Just a question: which core are you using?
Now there are so many..
https://github.com/stevstrong/Arduino_S … F4_variant
to use codes from the branch, the easier way is to simply use git to checkout that branch
http://www.stm32duino.com/viewtopic.php … =80#p26483
note that if you do a clone of the repository, you would likely get ‘everything’ including the branch
before you start work on that branch (after a fetch/pull or clone), it is necessary to issue
git checkout Black_F4_variant
It happens when the code enters “setup()” at the address aa4. There is something weird at this address (first picture).
It comes to reservedexception9, which is handled at the address dd0 in the isrs file (second picture).
So the jump from main() to setup() at weird aa4 is causing the exception, imho
Around the aa4 there are 2 identical setup() labels with same creazy instructions on even and odd addresses.
From aad the asm FPU enable starts, then the delay(100) and then Serial.begin.
Before the setup() there are the math functions consisting mostly from fpu instr calls.
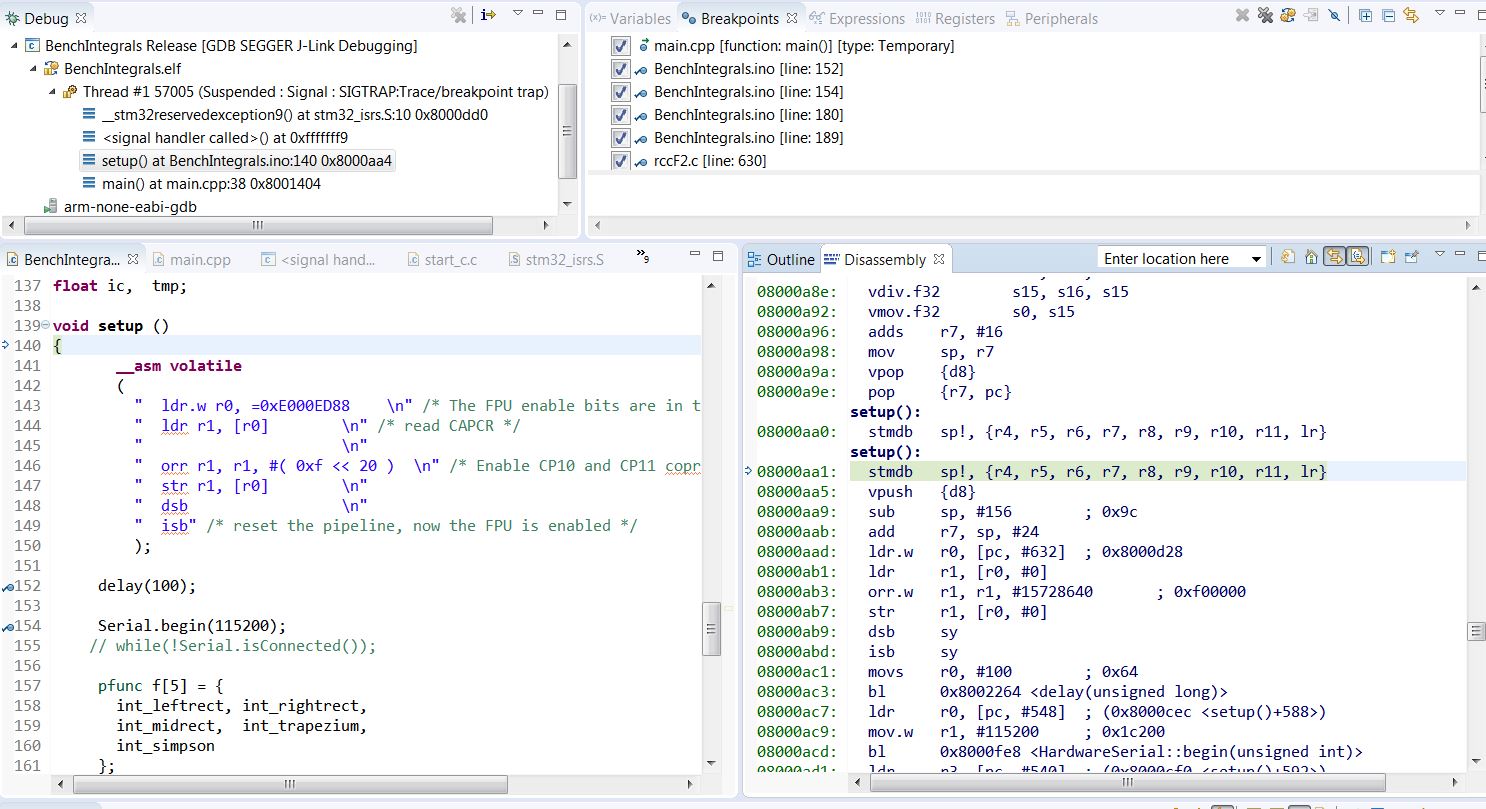
- Crash1.JPG (212.25 KiB) Viewed 331 times
i did something tedious, moved all the subroutines below setup() and loop(), declare function prototypes at the top, didn’t work, the led is still dark.
the typedefs remain there though
The math code before setup() finishes fine, then nop, then setup() etc.
The instructions around setup() seem to be clean. On the above crash scene there is a big mess +/-2 instr big around the setup().
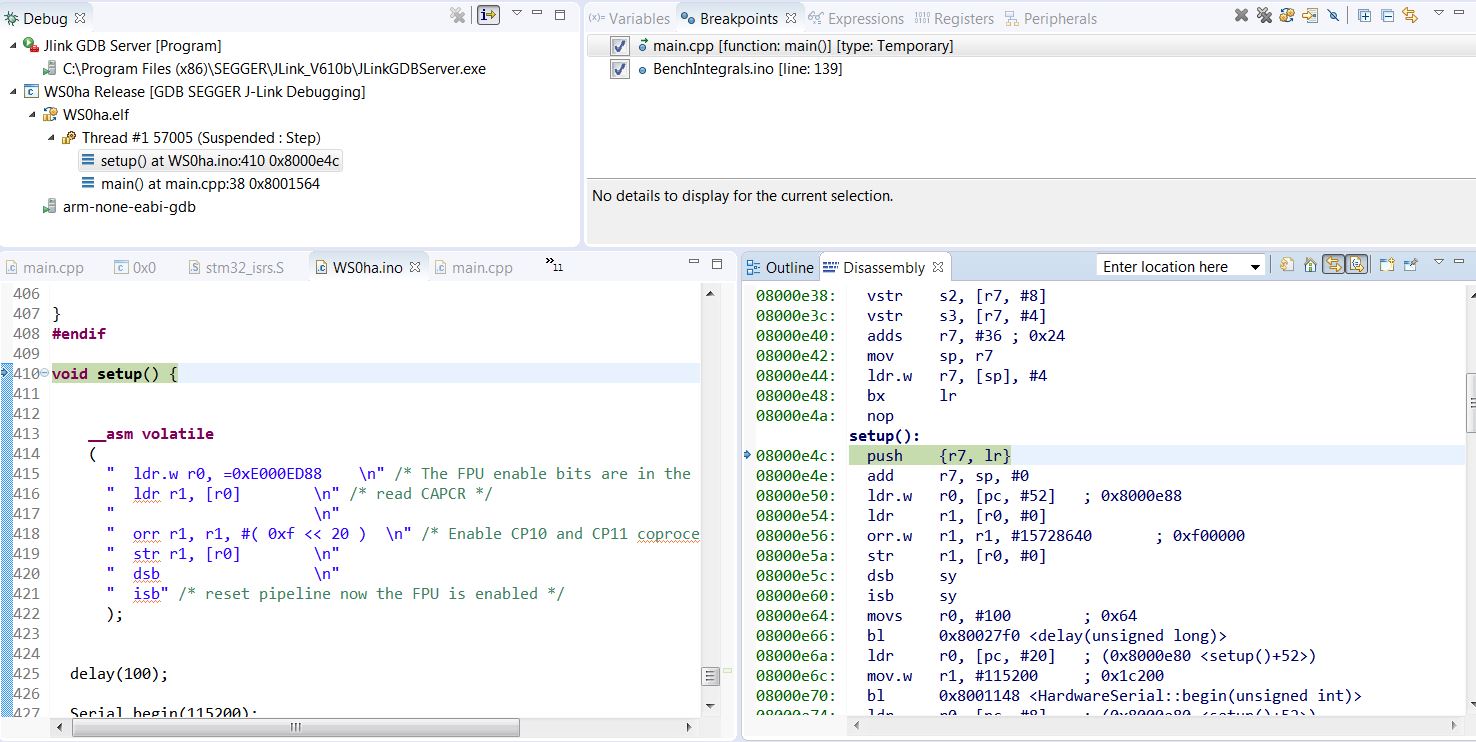
- Whet OK setup.JPG (176.22 KiB) Viewed 320 times
yes it works! 1 minute i’d upload it in a zip file here, note i’m using purely c/c++ file naming, the file integral_main.cpp contains setup() and loop() and would be renamed with an .ino suffix/file type
the floating point integral benchmark is in integral_float.cpp
uploaded the source codes, replace SerialUSB with Serial if you are using Serial.
press ‘g’ to start
WITH_FPU 1, optimization -Os (optimise size), debug off,v6.3.1-2017-q1-update
hardware floating point, single precision
Benchmark starts..
leftrect [2.0e+00 1.0e+01] num: 6.720000e-03, ana: 6.712139e-03
rightrect [2.0e+00 1.0e+01] num: 6.705779e-03, ana: 6.712139e-03
midrect [2.0e+00 1.0e+01] num: 6.712879e-03, ana: 6.712139e-03
trapezium [2.0e+00 1.0e+01] num: 6.712059e-03, ana: 6.712139e-03
simpson [2.0e+00 1.0e+01] num: 6.712050e-03, ana: 6.712139e-03
leftrect [-1.0e+00 -7.0e-01] num: -2.613795e-03, ana: -2.612248e-03
rightrect [-1.0e+00 -7.0e-01] num: -2.613944e-03, ana: -2.612248e-03
midrect [-1.0e+00 -7.0e-01] num: -2.613870e-03, ana: -2.612248e-03
trapezium [-1.0e+00 -7.0e-01] num: -2.612268e-03, ana: -2.612248e-03
simpson [-1.0e+00 -7.0e-01] num: -2.612271e-03, ana: -2.612248e-03
leftrect [1.0e+01 5.0e+01] num: 2.825554e-01, ana: 2.824790e-01
rightrect [1.0e+01 5.0e+01] num: 2.824033e-01, ana: 2.824790e-01
midrect [1.0e+01 5.0e+01] num: 2.824792e-01, ana: 2.824790e-01
trapezium [1.0e+01 5.0e+01] num: 2.824792e-01, ana: 2.824790e-01
simpson [1.0e+01 5.0e+01] num: 2.824791e-01, ana: 2.824790e-01
leftrect [0.0e+00 1.0e+01] num: 6.603576e-01, ana: 6.601052e-01
rightrect [0.0e+00 1.0e+01] num: 6.598577e-01, ana: 6.601052e-01
midrect [0.0e+00 1.0e+01] num: 6.601063e-01, ana: 6.601052e-01
trapezium [0.0e+00 1.0e+01] num: 6.601086e-01, ana: 6.601052e-01
simpson [0.0e+00 1.0e+01] num: 6.601073e-01, ana: 6.601052e-01
Benchmark ends, elapsed 2383 msecs
you can take a look at the source codes, uploaded in the last post
There is nothing before setup(): probably vectors, then __do_global_dtors_aux: and frame_dummy.
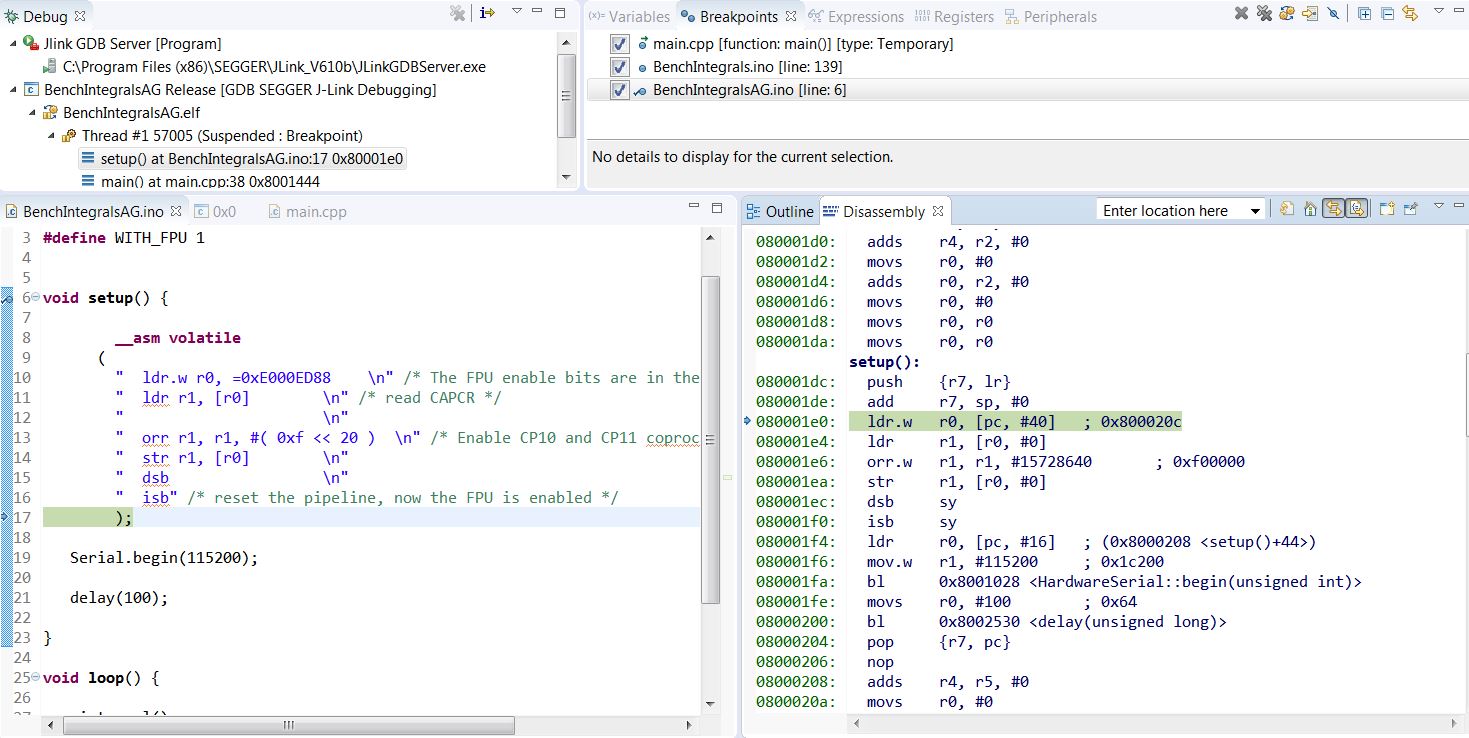
- IntegrAG.JPG (179.39 KiB) Viewed 307 times
http://stackoverflow.com/questions/2711 … ting-point
Benchmark starts..the source is in integral_float.cpp
in either setup() or loop()
u’d need to call integral() which is the benchmark code
do upload a version that’s probably more stm32duino ‘compliant’ as mine is pretty much a scratch
oops strange, doesn’t seem relevant it runs here, i mean integral()
![]()
the defines used as extracted from a makefile
mcpu=cortex-m4 -mthumb -mfloat-abi=hard -mfpu=fpv4-sp-d16 -Os
-fmessage-length=0 -fsigned-char -ffunction-sections -fdata-sections -ffreestanding -fno-move-loop-invariants
-Wall -Wextra
-DSTM32_HIGH_DENSITY
-DSTM32F4
-DBOARD_black_f4
-DCONFIG_MAPLE_MINI_NO_DISABLE_DEBUG
-DDEBUG_LEVEL=DEBUG_NONE
-DVECT_TAB_ADDR=0x8000000
-DVECT_TAB_BASE
-DF_CPU=168000000L
-DSERIAL_USB
-DUSB_VID=0x1EAF
-DUSB_PID=0x0004
-DUSB_MANUFACTURER="Unknown"
-I"/opt3/src/workspace/STM32F4duinoblinky/STM32F4/cores/maple"
-I"/opt3/src/workspace/STM32F4duinoblinky/STM32F4/cores/maple/libmaple"
-I"/opt3/src/workspace/STM32F4duinoblinky/STM32F4/cores/maple/libmaple/usbF4/VCP"
-I"/opt3/src/workspace/STM32F4duinoblinky/STM32F4/cores/maple/libmaple/usbF4/STM32_USB_OTG_Driver/inc"
-I"/opt3/src/workspace/STM32F4duinoblinky/STM32F4/cores/maple/libmaple/usbF4/STM32_USB_Device_Library/Core/inc"
-I"/opt3/src/workspace/STM32F4duinoblinky/STM32F4/cores/maple/libmaple/usbF4/STM32_USB_Device_Library/Class/cdc/inc"
-I"/opt3/src/workspace/STM32F4duinoblinky/STM32F4/cores/maple/libmaple/usbF4"
-I"/opt3/src/workspace/STM32F4duinoblinky/STM32F4/variants/black_f407vet6"
-std=gnu++11
-fabi-version=0 -fno-exceptions -fno-rtti -fno-use-cxa-atexit -fno-threadsafe-statics
-MMD -MP -MF"$(@:%.o=%.d)" -MT"$(@)" -c -o "$@" "$<"
I put integral.h and integral_float.cpp and AG.ino into the same project dir.
Compiles 50k without error or warning.
It prints so the Serial works.
Enclosed my code without USB and LEDS.
- AGsetup.JPG (24.65 KiB) Viewed 291 times
press ‘g’ to start
i compiled this in arduino ide 1.8.2, the board selected is “stm32 discovery f407”
note that SerialUSB exists and is defined, i do not need to substitute SerialUSB with Serial
4.8.3-2014q1 hardware floating point, parameters based on platforms.txt and boards.txt for above board
Benchmark starts..
leftrect [2.0e+00 1.0e+01] num: 6.720000e-03, ana: 6.712139e-03
rightrect [2.0e+00 1.0e+01] num: 6.705779e-03, ana: 6.712139e-03
midrect [2.0e+00 1.0e+01] num: 6.712879e-03, ana: 6.712139e-03
trapezium [2.0e+00 1.0e+01] num: 6.712058e-03, ana: 6.712139e-03
simpson [2.0e+00 1.0e+01] num: 6.712050e-03, ana: 6.712139e-03
leftrect [-1.0e+00 -7.0e-01] num: -2.613795e-03, ana: -2.612248e-03
rightrect [-1.0e+00 -7.0e-01] num: -2.613944e-03, ana: -2.612248e-03
midrect [-1.0e+00 -7.0e-01] num: -2.613870e-03, ana: -2.612248e-03
trapezium [-1.0e+00 -7.0e-01] num: -2.612268e-03, ana: -2.612248e-03
simpson [-1.0e+00 -7.0e-01] num: -2.612271e-03, ana: -2.612248e-03
leftrect [1.0e+01 5.0e+01] num: 2.825554e-01, ana: 2.824790e-01
rightrect [1.0e+01 5.0e+01] num: 2.824033e-01, ana: 2.824790e-01
midrect [1.0e+01 5.0e+01] num: 2.824792e-01, ana: 2.824790e-01
trapezium [1.0e+01 5.0e+01] num: 2.824792e-01, ana: 2.824790e-01
simpson [1.0e+01 5.0e+01] num: 2.824791e-01, ana: 2.824790e-01
leftrect [0.0e+00 1.0e+01] num: 6.603576e-01, ana: 6.601052e-01
rightrect [0.0e+00 1.0e+01] num: 6.598577e-01, ana: 6.601052e-01
midrect [0.0e+00 1.0e+01] num: 6.601063e-01, ana: 6.601052e-01
trapezium [0.0e+00 1.0e+01] num: 6.601086e-01, ana: 6.601052e-01
simpson [0.0e+00 1.0e+01] num: 6.601073e-01, ana: 6.601052e-01
Benchmark ends, elapsed 8136 msecs
I am getting __stm32reservedexception9 in
prntf("%10s [%1.1e %1.1e] num: %1.6e, ana: %1.6e\n",
names[i], ivals[2*j], ivals[2*j+1], ic, tmp);i’m hitting up some compile errors when i add the hardware float compile flags in boards.txt
discovery_f407.build.extra_flags=-DMCU_STM32F406VG -mthumb -mcpu=cortex-m4 -mfloat-abi=hard -mfpu=fpv4-sp-d16 -Os -DSTM32_HIGH_DENSITY -DSTM32F2 -DSTM32F4 -DBOARD_discovery_f4-mfloat-abi=hard -mfpu=fpv4-sp-d16 -fsingle-precision-constantvoid prntf(char *fmt, ... ){
char buf[128]; // resulting string limited to 128 chars
va_list args;
va_start (args, fmt );
vsnprintf(buf, 128, fmt, args);
va_end (args);
for(int i=0;i<128;i++) {
if(buf[i]=='\0') break;
if(buf[i]=='\n')
SerialUSB.println();
else
SerialUSB.write(buf[i]);
}
}Yes it crashes with mine version too.
I m not using USBSerial.
So what is the trick with your version which works??
It compiles. I use Serial instead of USBSerial, so the .bins are not the same size.
It prints, so it compiles and links all components, it seems.
It crashes while printing results.
Both prntf versions tried.
currently only the software float part of it works in arduino ide
signing off for now
-Os -g, 4.8.3-2014q1, -mfloat-abi=hard -mfpu=fpv4-sp-d16 -fsingle-precision-constant, FPUon, 168MHz,
Benchmark starts..
left num: 6.7200002e-3 ana: 6.7121386e-3
righ num: 6.7057795e-3 ana: 6.7121386e-3
midr num: 6.7128791e-3 ana: 6.7121386e-3
trap num: 6.7120594e-3 ana: 6.7121386e-3
simp num: 6.7120509e-3 ana: 6.7121386e-3
left num: -2.6137950e-3 ana: -2.6122405e-3
righ num: -2.6139435e-3 ana: -2.6122405e-3
midr num: -2.6138706e-3 ana: -2.6122405e-3
trap num: -2.6122679e-3 ana: -2.6122405e-3
simp num: -2.6122713e-3 ana: -2.6122405e-3
left num: 2.8255537e-1 ana: 2.8247904e-1
righ num: 2.8240325e-1 ana: 2.8247904e-1
midr num: 2.8247917e-1 ana: 2.8247904e-1
trap num: 2.8247917e-1 ana: 2.8247904e-1
simp num: 2.8247909e-1 ana: 2.8247904e-1
left num: 6.6035757e-1 ana: 6.6010518e-1
righ num: 6.5985774e-1 ana: 6.6010518e-1
midr num: 6.6010627e-1 ana: 6.6010518e-1
trap num: 6.6010856e-1 ana: 6.6010518e-1
simp num: 6.6010732e-1 ana: 6.6010518e-1
Benchmark ends, elapsed 924 msecs
The vsnprintf is dangerous.We must get rid of it.
See below the loop.
- vsnprtf issue.JPG (154.32 KiB) Viewed 282 times
I will modify the stuff later on to print results after the computation. But it is ok for now.
Interested to see your results..
yup it works
v6.3.1-2017-q1-update, optimization -O2 (optimise more), debug off, note -fsingle-precision-constant is not sspecified
hardware floating point, single precision, WITH_FPU 1,
Hello 1, The Benchmark starts..
left num: 6.7200002e-3 ana: 6.7121386e-3
righ num: 6.7057795e-3 ana: 6.7121386e-3
midr num: 6.7128791e-3 ana: 6.7121386e-3
trap num: 6.7120594e-3 ana: 6.7121386e-3
simp num: 6.7120504e-3 ana: 6.7121386e-3
left num: -2.6137950e-3 ana: -2.6122479e-3
righ num: -2.6139435e-3 ana: -2.6122479e-3
midr num: -2.6138706e-3 ana: -2.6122479e-3
trap num: -2.6122679e-3 ana: -2.6122479e-3
simp num: -2.6122713e-3 ana: -2.6122479e-3
left num: 2.8255537e-1 ana: 2.8247904e-1
righ num: 2.8240327e-1 ana: 2.8247904e-1
midr num: 2.8247923e-1 ana: 2.8247904e-1
trap num: 2.8247917e-1 ana: 2.8247904e-1
simp num: 2.8247907e-1 ana: 2.8247904e-1
left num: 6.6035757e-1 ana: 6.6010518e-1
righ num: 6.5985774e-1 ana: 6.6010518e-1
midr num: 6.6010627e-1 ana: 6.6010518e-1
trap num: 6.6010856e-1 ana: 6.6010518e-1
simp num: 6.6010732e-1 ana: 6.6010518e-1
Benchmark ends, elapsed 2305 msecs
-Os -g, 4.8.3-2014q1, -mfloat-abi=hard -mfpu=fpv4-sp-d16 -fsingle-precision-constant, FPUon, 240MHz
Benchmark starts..
left num: 6.7200002e-3 ana: 6.7121386e-3
righ num: 6.7057795e-3 ana: 6.7121386e-3
midr num: 6.7128791e-3 ana: 6.7121386e-3
trap num: 6.7120594e-3 ana: 6.7121386e-3
simp num: 6.7120509e-3 ana: 6.7121386e-3
left num: -2.6137950e-3 ana: -2.6122405e-3
righ num: -2.6139435e-3 ana: -2.6122405e-3
midr num: -2.6138706e-3 ana: -2.6122405e-3
trap num: -2.6122679e-3 ana: -2.6122405e-3
simp num: -2.6122713e-3 ana: -2.6122405e-3
left num: 2.8255537e-1 ana: 2.8247904e-1
righ num: 2.8240325e-1 ana: 2.8247904e-1
midr num: 2.8247917e-1 ana: 2.8247904e-1
trap num: 2.8247917e-1 ana: 2.8247904e-1
simp num: 2.8247909e-1 ana: 2.8247904e-1
left num: 6.6035757e-1 ana: 6.6010518e-1
righ num: 6.5985774e-1 ana: 6.6010518e-1
midr num: 6.6010627e-1 ana: 6.6010518e-1
trap num: 6.6010856e-1 ana: 6.6010518e-1
simp num: 6.6010732e-1 ana: 6.6010518e-1
Benchmark ends, elapsed 633 msecs..
The quick guide on setting the FPU ON on STM32F407 boards under STM32duino
Will be precised further on
In your platform.txt add
-mfloat-abi=hard -mfpu=fpv4-sp-d16 -fsingle-precision-constant
i’d think at some ‘future’ time enable_fpu() can perhaps go into libmaple as a ‘convenience function’, i.e. only sketches that needs them calls it
i’m not sure if calling it in init() may cause more power consumption etc, or more importantly if it gets called on the f103 it may lead to a hard fault/exception. hence, that’d be left to the user/sketch who needs it to call it
i’ve a version that’s sort of ‘pretty printed’
//enable the fpu (cortex-m4 - stm32f4* and above)
//http://infocenter.arm.com/help/topic/com.arm.doc.dui0553a/BEHBJHIG.html
void enablefpu()
{
__asm volatile
(
" ldr.w r0, =0xE000ED88 \n" /* The FPU enable bits are in the CPACR. */
" ldr r1, [r0] \n" /* read CAPCR */
" orr r1, r1, #( 0xf << 20 )\n" /* Set bits 20-23 to enable CP10 and CP11 coprocessors */
" str r1, [r0] \n" /* Write back the modified value to the CPACR */
" dsb \n" /* wait for store to complete */
" isb" /* reset pipeline now the FPU is enabled */
);
}
The Benchmark shows the speed and the accuracy of the math lib.
The Benchmark is not easy to optimize out.
Changes:
1. Added precise results from Wolfram Alfa
2. Printing the results is now off the calculation loop.
-O3 -g, 4.8.3-2014q1, -mfloat-abi=hard -mfpu=fpv4-sp-d16 -fsingle-precision-constant, FPU on, Black F407ZET @240MHz
Numerical Integration Benchmark starts..
Single Precision with FPU, v1.0
F1 Result: 0.00671211394423041159587
leftrect num: 6.720000e-3 ana: 6.712139e-3
righrect num: 6.705780e-3 ana: 6.712139e-3
midrect num: 6.712879e-3 ana: 6.712139e-3
trapezium num: 6.712059e-3 ana: 6.712139e-3
simpson num: 6.712051e-3 ana: 6.712139e-3
F2 Result: -0.00261227114510560413684
leftrect num: -2.613795e-3 ana: -2.612241e-3
righrect num: -2.613944e-3 ana: -2.612241e-3
midrect num: -2.613871e-3 ana: -2.612241e-3
trapezium num: -2.612268e-3 ana: -2.612241e-3
simpson num: -2.612271e-3 ana: -2.612241e-3
F3 Result: 0.28247911095899395473
leftrect num: 2.825554e-1 ana: 2.824790e-1
righrect num: 2.824032e-1 ana: 2.824790e-1
midrect num: 2.824792e-1 ana: 2.824790e-1
trapezium num: 2.824792e-1 ana: 2.824790e-1
simpson num: 2.824791e-1 ana: 2.824790e-1
F4 Result: 0.660105195382224847535
leftrect num: 6.603576e-1 ana: 6.601052e-1
righrect num: 6.598577e-1 ana: 6.601052e-1
midrect num: 6.601063e-1 ana: 6.601052e-1
trapezium num: 6.601086e-1 ana: 6.601052e-1
simpson num: 6.601073e-1 ana: 6.601052e-1
Benchmark ends, elapsed 616621 microsecs..
the trouble is on an f1 a user who runs it using soft float may need to wait > 10x that amount of time for the benchmark to complete
i’d suggest we can use micros() instead which is the time in microseconds and we can make do with less loops
in addition i found that __ARM_PCS_VFP is defined by gcc when compiling with the option -mfloat-abi=hard -mfpu=fpv4-sp-d16 hence, this could be used to determine if the user is compiling with hardware float specified in the compile options
#ifdef __ARM_PCS_VFP
#warning enabling harware fpu
enablefpu();
#else
#warning using software floating point
#endif
We may enhance it in the near future. The Benchmark is for an FPU, so an F1 user has to modify it for F1.
The Single Precision is not intended for numerical math, so the results will be off for several reasons.
With newer processors with DP FPU we may create Double version.
The Q is whether somebody will use it, so do not spend too much time with it..
P.
PS: updated the pretty printed asm
the trouble is on an f1 a user who runs it using soft float may need to wait > 10x that amount of time for the benchmark to complete
i’d suggest we can use micros() instead which is the time in microseconds and we can make do with less loops
in addition i found that __ARM_PCS_VFP is defined by gcc when compiling with the option -mfloat-abi=hard -mfpu=fpv4-sp-d16 hence, this could be used to determine if the user is compiling with hardware float specified in the compile options
#ifdef __ARM_PCS_VFP
#warning enabling harware fpu
enablefpu();
#else
#warning using software floating point
#endif
@407 experts and users: do start using the FPU and do publish your findings here in this thread. After gathering practical experience we will update.
Happy FPUing
-Os, -g, 4.8.3-2014q1, Maple Mini, No FPU, 72MHz
Numerical Integration Benchmark starts..
Single Precision with No FPU, v1.0
F1 Result: 0.00671211394423041159587
leftrect num: 6.720000e-3 ana: 6.712139e-3
righrect num: 6.705780e-3 ana: 6.712139e-3
midrect num: 6.712879e-3 ana: 6.712139e-3
trapezium num: 6.712058e-3 ana: 6.712139e-3
simpson num: 6.712050e-3 ana: 6.712139e-3
F2 Result: -0.00261227114510560413684
leftrect num: -2.613795e-3 ana: -2.612248e-3
righrect num: -2.613944e-3 ana: -2.612248e-3
midrect num: -2.613871e-3 ana: -2.612248e-3
trapezium num: -2.612268e-3 ana: -2.612248e-3
simpson num: -2.612271e-3 ana: -2.612248e-3
F3 Result: 0.28247911095899395473
leftrect num: 2.825554e-1 ana: 2.824790e-1
righrect num: 2.824033e-1 ana: 2.824790e-1
midrect num: 2.824792e-1 ana: 2.824790e-1
trapezium num: 2.824792e-1 ana: 2.824790e-1
simpson num: 2.824791e-1 ana: 2.824790e-1
F4 Result: 0.660105195382224847535
leftrect num: 6.603576e-1 ana: 6.601052e-1
righrect num: 6.598577e-1 ana: 6.601052e-1
midrect num: 6.601063e-1 ana: 6.601052e-1
trapezium num: 6.601086e-1 ana: 6.601052e-1
simpson num: 6.601073e-1 ana: 6.601052e-1
Benchmark ends, elapsed 23992225 microsecs..
but to leave something for the stm32 f1 users i’d suggest we have about 15-20secs for the f1 users
and we’d need to use micros() for timing, the ultimate would be when we’ve the loops complete in under 1usecs, we can then try to compete with the supercomputers
I only wanted to show to F1 users they system is really slow
Unfortunately, calling it in init() doesn’t guarantee that it will be called before any of the _pre_init constructors.
I only wanted to show to F1 users they system is really slow
for those that are slower too bad
Measurement in microsecs.
Updated on the first page (and elsewhere).
Q: hopefully the “float” in MapleMini profile does not mean the “double”. That would be a disaster..
https://en.wikipedia.org/wiki/Travellin … an_problem
in real time and win the races
http://wiki.evilmadscientist.com/TSP_art
https://www.google.com.sg/search?q=tsp+ … DUcQsAQIIQ
What use case do you see that using a double vs a float would be beneficial?
That is a good Q. See my short description on the front page of this thread.
The SP is good when talking a “standard” MCU usage as a process controller where the sensors gives you “a few digits inputs” (say 4-5). Or when you want to do DSP with audio or video (even today’s GPUs go DP).
In the moment as you want something more demanding, ie navigate from London to Sydney, you need DP.
If you want to predict position of celestial bodies, or a HAM satellite flyby, you need DP.
Or when implementing a GPS something, you need DP.
You can land safely on the Mars under SP control, or control the attitude/engine/flaps/maneuvers of an F-16 with SP, but you cannot navigate to Mars with SP, or to navigate from London to Sydney while sitting in an F-16 (when talking dead reckoning for example). Simply 6-7 “valid digits” with complex math is not enough for a lot of apps, especially when messing with transcendental functions (they return 5-6 valid digits usually).
For example you may try to make this quite simple calculations http://www.movable-type.co.uk/scripts/latlong.html with SP against DP, what would be the difference.
but i’d guess the f4 ‘platform’ is a niche of sorts, at least the performance is decent/good for these tests
for gps kind of things, i’d think double precision is needed for an accurate positioning. however if only a relative position is needed and in small metropolitan towns or cities, i’ve tried using the ‘the earth is flat’ approximation i.e. pythagoras theorem, and i’m able to pretty much ‘fake’ the distances between 2 points in a neighbourhood (say based on guess-itimate cell tower locations), it would certainly not work if we are on opposite sides of the spere ![]()
Even a compare ie. if( q == r ) may not work reliably, instead you have to use if ( (q < (r + epsilon)) or (q > (r – epsilon)) ).. to be sure it works.. Many $30 calculators use 25digits+ in order to find proper roots
With CMSIS DSP libs you may try FFT and such stuff. That will work nice. Maybe faster than with integers.. No problems with scaling, saturation, q15 conversions, etc. Just feed floats in and you get nice floats spectra out..
PS:
FFT 1024 points on F429:
q15 457us
q31 855us
SP float 547us
http://www.st.com/content/ccc/resource/ … 273990.pdf
Input/output is float (test signal from the example file).
-O3, -g, 4.8.3-2014q1, 168MHz
FFT.. elapsed 700 microsecs
FFT Magn.. elapsed 211 microsecs
FFT Bins.. elapsed 61 microsecs
You may see the tone at 230 is still visible (luckily not hidden in the noise background) despite the large numerical noise of float.
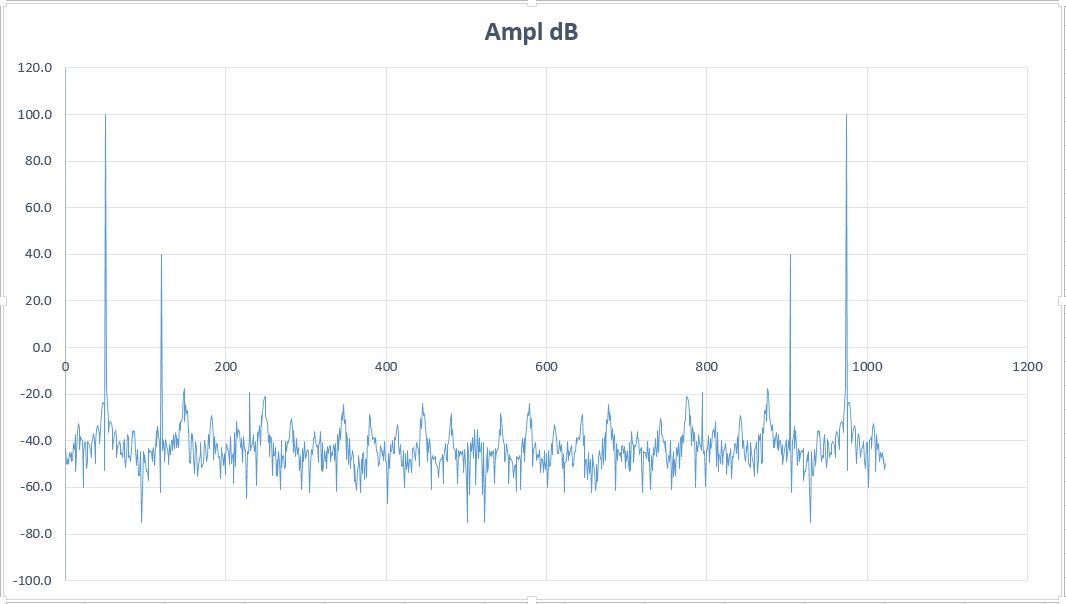
- FFT 3 tones.JPG (63.11 KiB) Viewed 781 times
..
#if defined (__GNUC__) && defined (__VFP_FP__)
#warning enabling harware fpu
__asm volatile
(
" ldr.w r0, =0xE000ED88 \n" /* The FPU enable bits are in the CPACR. */
" ldr r1, [r0] \n" /* read CAPCR */
" orr r1, r1, #( 0xf << 20 )\n" /* Set bits 20-23 to enable CP10 and CP11 coprocessors */
" str r1, [r0] \n" /* Write back the modified value to the CPACR */
" dsb \n" /* wait for store to complete */
" isb" /* reset pipeline now the FPU is enabled */
);
#else
#warning using software floating point
#endif
/* Run initializers. */
__libc_init_array();
..
apparently this particular define won’t show up with -mthumb -mcpu=cortex-m4 -mfloat-abi=softfp -mfpu=fpv4-sp-d16 (i.e. software floats)
or if it is simply left out, i’d assume eclipse or rather perhaps gcc simply use the software floating points if nothing is specified
It does mean the FPU uses the standard registers for parameters passing to the FPU. It is for compatibility reasons.
Both -hard and -softfp use the FPU.
It may happen the -softfp with FPU off will use software math routines, not verified yet.
No hardware fpu used:
__SOFTFP__ 1
__ARM_PCS 1
http://infocenter.arm.com/help/topic/co … 21827.html
__ARM_PCS 1 Set for 32-bit targets only. Set to 1 if the default procedure calling standard for the translation unit conforms to the base PCS.
__ARM_PCS_VFP 1 Set for 32-bit targets only. Set to 1 if the default procedure calling standard for the translation unit conforms to the VFP PCS. That is, -mfloat-abi=hard.
__SOFTFP__ 1 Set to 1 when compiling with software floating-point on 32-bit targets. Set to 0 otherwise.
http://ta.twi.tudelft.nl/users/vuik/wi2 … sters.html
#if defined(__GNUC__) && (__ARM_PCS==1 || __ARM_PCS_VFP==1)
#warning enabling harware fpu
enable_fpu();
#endif
...
http://support.raisonance.com/content/h … -cortex-m4
The GCC toolchain offers 3 methods to handle floating-point on STM32F4xx. The correct method depends on your application and its requirements:
Emulated float (-mfloat-abi=soft option) which disables the FPU
Hardware FPU (-mfloat-abi=softfp option) with standard EABI parameter passing
Hardware FPU (-mfloat-abi=hard option) with specific parameter passing
the thing i’m not sure is: if none of those flags are specified and that there are float (single precision calculations) in the codes, which is the option that gcc would use as the default? if the default is emulated float i.e. skipping fpu altogether, we are probably safe (i.e. we won’t have the __ARM_PCS==1 || __ARM_PCS_VFP==1 ) flags, as either of them being there means hooking up the fpu or a hard fault would occur since the call would simply fall flat (fpu disabled)
if the default is -mfloat-fbi=soft (i.e. software float emulation) adding hardware float would then be simply selecting a ‘variant’ in which we can put those -mfloat-abi=softfp or -mfloat-abi=hard options in the particular boards.txt variant section
signing off for now ![]()


