Cheers, Ollie
viewtopic.php?f=9&t=1146&start=10#p15440
Posting by @slammer
No arduino functions are implemented yet, just the skeleton and a “nice” building system for opencm3 projects inside arduino IDE.
I hope to find the time to complete some functions, to evaluate the platform.
Was it a design decision to not put the linker files in the variant folder ?
I’ve noticed you put them in the libopencm3/lib folder.
I wanted to add a Maple Mini variant, and add a new linker script with the bootloader offset, but wasnt sure that the libopencm3/lib folder was the best place to put this
I guess it would be possible to have linker files named something like stm32f103cb_bootloader.ld so that they could be used by both the generic stm32f103cb and the Maple mini
(Note. I know that if I link that way, I’d need to manually get the Maple mini into DFU upload mode and add the DFU upload tools etc etc)
Thanks
Roger
It would be nice to combine that functionality with the wide acceptance of Arduino IDE. If the legal licensing issues can be solved, then this combined solution could be used in business level applications in addition of the existing maker products.
Cheers, Ollie
Cheers, Ollie
From the other side I dont like halmx, horrible naming of functions, passing even simple arguments with weird structures with difficult names, no abstraction, bloated even for simple procedures, . Only the rcc clock setup takes more than 3KB!!!
The only viable final solution is to use cmsis only and access the registers directly building your own low level functions.
libopencm3 is OK for mature members of stm32, and an easy way to start with F103, I see this as an opportunity to know better the stm32 family and I think that after this process it will be easier to use cmsis.
RogerClark wrote:@slammer & @vassilis
Was it a design decision to not put the linker files in the variant folder ?
I’ve noticed you put them in the libopencm3/lib folder.
I totally agree with your assessment. There is a strong analogy with our historical case, where we started to modify Leaf Lab Library to make it work within Arduino IDE framework. Now we have a chance to add value to LibOpenCM3 by adding the missing functionality and to make it work with Arduino.
I know that I could follow the progress of your testing through GitHub, but I am interested about your plans in NVIC vector handling. I am in process of doing similar process by using LOCM3 with EmBitz and have not yet solved the issues related in interrupt management.
Cheers, Ollie
mbed is a truly unified API across almost all ARM chips, and is based on top of cmsis/hal of each vendor (see supported platforms: https://developer.mbed.org/platforms )
While the mbed upper layer (C++ layer) is not important for us, the lower C API is very interesting, and it is possible to build on top of it, the Arduino Core. The C api hides all hardware specific stuff and provides a unified (or almost unified) layer, for example:
uint32_t gpio_set(PinName pin);
void serial_init(serial_t *obj, PinName tx, PinName rx);
int serial_getc(serial_t *obj);
void spi_init(spi_t *obj, PinName mosi, PinName miso, PinName sclk, PinName ssel);
int spi_master_write(spi_t *obj, int value);
int spi_slave_receive(spi_t *obj);
...
Re: Using mbed as a underlying API
That’s what RedBearLabs did for their nRF51 board. https://github.com/RedBearLab/nRF51822-Arduino
I have cloned and use that repo for the nRF51 but it seems to be based on quite an old snapshot of mbed, and they (mbed) seem to have refactored a lot of stuff over the last year.
So although you could base on mbed, its hard to know if its now stable, i.e if they refactor again, it won’t be possible simply to take another snapshot and replace the original copy that a core was based on.
I think other people e.g. @martin have more experience of mbed and can perhaps give a better opinion of whether its actually any good or not.
I only use it if I have to, as I don’t like cloud based systems, as you are dependent on their systems working and your internet connection working etc
The SDK is here and there is no reason to use online compilers, it was very easy for me to make a Codeblocks project with all mbed sources for building examples with GCC (requires GCC V5 – if someone wants the project pm).
I dont know also how stable is, but it is a very active project. If someone is more experienced with mbed his opinion would be very usefull.
FYI: From yesterday, bluepill, is officially supported by mbed as TARGET_BLUEPILL_F103C8 ![]() https://github.com/mbedmicro/mbed/tree/ … ILL_F103C8
https://github.com/mbedmicro/mbed/tree/ … ILL_F103C8
RogerClark wrote:
Re: Using mbed as a underlying API
That’s what RedBearLabs did for their nRF51 board. https://github.com/RedBearLab/nRF51822-Arduino
I think other people e.g. @martin have more experience of mbed and can perhaps give a better opinion of whether its actually any good or not.
Do you think that the use of mbed lower level API is viable solution for a more unified arduino core? What is your opinion about this?
While the mbed C++ sources are in the core directory, arduino core functions are using the lower level API even the cmsis in some simple functions (they dont care about compatibility). It is certain that RedBearLabs developers have made a serious try to optimize the mbed hal for their purpose.
They have also updated the mbed sources to the latest version.
Thanks for the review of the RBL core
Someone else said to me that they thought RBL had updated recently, so I will probably fork their repo again , as I have a modified fork, but it would need modification to work if RBL changed their structure.
I know originally RBL seem to have organised the mbed folders when they made their repo, so I’ll take another look and now see if the organisation is closer to that of the mbedmicro github repo.
On other hand, the LOCM3 looks better the more I am using it. For an overview, look the documentation that was derived from the source code at http://libopencm3.github.io/docs/latest/html/. For example, the F7 support is quite extensive for the day we will have cheap F745/F746 boards.
Cheers, Ollie
mbed seem to have an internal API https://developer.mbed.org/handbook/mbe … -internals, which could be called from a STM32 core, but there is note on their site that this API is subject to change
Anyway, the code size of mbed projects is a bit increased. I manage to wipe out all C++ classes, and to use only the C API. I made some tests with gpio and uarts, at about 5-6kb of binary code. It seems that some functions of stdlib are linked without obvious reason but I am trying on this. Most of the code is the rcc initialization code from Halmx. Not bad.
Even though mbed is run by ARM, the development process tends more towards a bazaar than a cathedral. They accept pretty much any patches that sound reasonable and pass the automated regression tests. This is great for expanding support to new platforms, but it also means that the quality level varies quite a bit between platforms. For example, the STM32 mbed-enabled Nucleo boards came out two years ago, but only got official CAN API support a month ago.
In the case of ST specifically, I think that most of the code is a thin wrapper around the HAL (and now CubeMX) code. In a sense, what you get is the CubeMX code repackaged for the mbed API. For example, the thread on this GitHub issue sheds light onto the process when they update the ST code:
https://github.com/mbedmicro/mbed/issues/1096
Regarding libopencm3, its goals are pretty firmly oriented towards providing thin wrappers over register-level access to peripherals. With the exception of the USB stack, the APIs are not structured for compatibility between series. There is no single API function that can be used to say, configure a GPIO pin as an output on both an F1 chip and an F0 chip. It’s essentially an open-source CMSIS alternative (before mbed’s licensing forced ARM to open up CMSIS under more permissive licenses) that happens to have a USB stack attached to it.
In terms of manpower, the libopencm3 community is definitely much smaller than the mbed community. The number of open pull requests is a pretty good indicator that the maintainers (maintainer, really) don’t have the bandwidth to code-review and test most community changes. It’s fairly common at this point for me to stumble into a bug and discover that someone else already ran into it a year ago and proposed a solution which was not integrated, because no-one else was available that uses the feature and could test the changes.
There’s been some discussion in the last few days about unicore-mx, a fork that tries to address some of these issues:
https://gitter.im/libopencm3/discuss?at … 9e4a08eb4a
If you don’t feel like wading through chat logs, here’s a direct link the unicore-mx GitHub repo:
https://github.com/insane-adding-machines/unicore-mx
TLDR: mbed has a HAL, but for better or for worse, it’s repackaged CubeMX code.
libopencm3 isn’t really a HAL and is somewhat anemic, but there’s a fork that wants to build it into a HAL.
If you don’t feel like wading through chat logs, here’s a direct link the unicore-mx GitHub repo:
https://github.com/insane-adding-machines/unicore-mx
I started to do my Wiki using LOCM3 with EmBitz. Do you have a recommendation, that I should switch to unicore-mx?
There has been some discussions that the LOCM3 support has been waning after a stellar start some years ago. Could unicore-mx be a proper alternative as modern LOCM3.
From engineering point of view, I strongly prefer the style used in LOCM3 compared to anything coming from ARM or STM.
Cheers, Ollie
There has been some discussions that the LOCM3 support has been waning after a stellar start some years ago. Could unicore-mx be a proper alternative as modern LOCM3.
From engineering point of view, I strongly prefer the style used in LOCM3 compared to anything coming from ARM or STM.
I agree with the ideas behind the unicore-mx fork, but I think it may be too early to start using it, as their plan inherently requires many sweeping, breaking changes. Personally, I’m waiting for a more concrete roadmap before getting involved.
Of course the direction of the project is correct. I will be watching the progress….
A Code::Blocks building system for F103/F401 is working for those that don’t use arduino IDE.
A Code::Blocks building system for F103/F401 is working for those that don’t use arduino IDE.
I don’t have any windows running machine…. (I am waiting a linux version of Embitz).
In EmBitz forum there have been repeated discussions that several users would like to use the IDE in Linux, but the developer (Gerard Zagema) has not found a business justification for the additional effort. This free tool has been developed by him and maintained by him on funding from the volunteer donations.
With the Rapsberry Pi and Espreffif products, there is an increasing pressure to move the MCU development platforms to Linux.
Perhaps, I will take a second look and reevaluate the latest CodeBlocks against the latest EmBlocks/EmBitz and start my migration from W10 to Linux.
Cheers, Ollie
For the first, there is no problem with codeblocks, as you can define all project’s options manually (maybe this is a bit tricky for the first time).
For the debugger, as I know it is possible to use C::B as gdb frontend without problems (without dedicated register viewers of Embitz).
i’d settle for the Code::Blocks building system, did go looking, but failed to find anything.
any chance of a link ?
stephen
In the repository https://github.com/Serasidis/arduino_opencm3, inside test directory there is a C::B project that builds the arduino core and some small programs (as targets in a multitarget project). This is my testbed for developing. You can take it as a base for STM32 development, contains settings for F1 and F4 families.
All you have to do before opening of the project is to define the ARM compiler, for compatibility reasons I am using the toolchain provided by arduino but you can use any newer toolchain from here https://launchpad.net/gcc-arm-embedded . Here is the screenshot for toolchain definition from my system:
I am part of the team that started the unicore-mx fork of libopencm3 very recently.
In this thread already some concerns we share about libopencm3 were discussed.
Devan: yes indeed, in reworking the API to our liking, we will break some things.
How bad is this for current use? That depends on wether you prefer the added functionality of
unicore-mx over the infrequent updates on libopencm3.
At the moment of forking, in ~6 months we managed to get 270 commits ahead of libopencm3 master.
Most of those out of libopencm3s own PR backlog. Some from other sources that never got shared upstream.
Others we added because we needed the functionality for our main project, frosted, a free POSIX-compliant
embedded OS.
Another option is that we could keep backwards compatibility for a while, to accomodate the community.
Our goal is to define the API top down and have a stable API first and foremost.
In doing so we want to attempt to create a more unified API, not just within one family, but
across vendors. The path to there will break things, however, if suggestions are made about how
to go about it to minimize user pain, we want to take those into account.
Slammer: A roadmap is to be expected in 3-4 weeks. At this moment we are trying to sollicit as much
comments on our ideas as possible. We welcome any ideas or concerns you, the community, may have.
Besides the API, we also feel that added functionality today is preferable over demanding perfection,
which never arrives. We want to respond swiftly to issues and PRs, and foster a healthy community around
this. We are not the ones with the answers. You are.
If anyone is interested in joining the discussion and general fun, our github issue tracker is open
for public, and so is our IRC channel on freenode, #unicore-mx.
Our mailinglist will be active shortly as well.
All hail Eris!
Thanks for the update.
I am aware that your main focus is to address the issues detected in libopencm3. Because the CodeBlocks is not necessary known among the STM32 developers, I am wondering, if the unicore-mx development could include examples how to
– Use unicore-mx in CodeBlocks running in Ubuntu or Debian
– Use unicore-mx in CodeBlocks running in W10 or OS-X
For many “lazy” developers, it would be really nice to be able to download and install everything with few steps and to have a confidence that everything works well together.
For the past few days, I have been working with latest Ubuntu LTS in VirtualBox running the latest CodeBlocks using the latest arm-none-eabi tools and libraries. So far, I have not been able to complete a single STM32F103 project.
Cheers, Ollie
Thanks for the update.
I am watching the progress of unicore-mx with great interest.
FYI the development of the core goes well, me and Vassilis we are working hard to build a minimal core.
Until now we have systimer (for millis, delay etc), digital I/O, SPI and UARTS. The SPI code is not very optimized yet, but it can run the Adafruit ILI9341 library almost untouched. The UART code uses IRQ for receive/transmit using the stock (from Arduino official core files) RingBuffers class (IMO is not optimized well). For our development we are using the Bluepill and the NucleoF401RE for now ( I am waiting a NucleoL476)
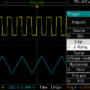
Here is the output of @simonf program from here: viewtopic.php?f=3&t=1189#p15004
AT Baudrate it Takes: -300 , 237uS. To send 1 char it should take uS :33333
AT Baudrate it Takes: -1200 , 237uS. To send 1 char it should take uS :8333
AT Baudrate it Takes: -2400 , 237uS. To send 1 char it should take uS :4166
AT Baudrate it Takes: -4800 , 237uS. To send 1 char it should take uS :2083
AT Baudrate it Takes: -9600 , 237uS. To send 1 char it should take uS :1041
AT Baudrate it Takes: -19200 , 237uS. To send 1 char it should take uS :520
AT Baudrate it Takes: -38400 , 237uS. To send 1 char it should take uS :260
AT Baudrate it Takes: -57600 , 240uS. To send 1 char it should take uS :173
AT Baudrate it Takes: -115200 , 243uS. To send 1 char it should take uS :86
My pleasure!
@Ollie,
I think that is a nice suggestion, and I think yes, we could ![]()
Given however that our current dev team does not use IDEs, we will have to rely on the community to provide those examples ![]()
But we are all for making it nice and easy for beginners to get going!
I need to do some final work on the libopencm3-examples repository (such as renaming) and will put the “new” unicore-mx-examples repository online shortly. We can promise this: any PR will be taken seriously, and if possible, merged.
@Slammer,
Also my pleasure! I’ll check out the arduino_opencm3 repository, I am curious about how you guys go about things ![]()
Thanks for your LOCM3/ATM32duino work and encouragement to use Linux and CodeBlocks. After several hours of frustration my conclusion is that CodeBlocks has no real benefit over the native Linux development environment with text editors, make files, and GDB. With this additional exposure, I do remember why I selected EmBlocks in first place over CodeBlocks. Without doubt, CodeBlocks is an excellent general purpose development platform, but it is lacking the native support for embedded control development.
brabo wrote:
Given however that our current dev team does not use IDEs, we will have to rely on the community to provide those examples ![]()
Yes, that is the plan. We’ll make a roadmap within 3-4 weeks, and then we will aim to set a date for a first stable API release.
As I said earlier, if there is interest to keep backwards compatibility for a while we can take that into account and try to accomodate that.
Hope that answers your question to satisfaction ![]()
During development of arduino core, as I am working on F1 and F4 boards, there are difficulties almost on every step. The libopencm3 is strictly “register oriented” and the user must know very well the hardware in register level not in operations level, it is almost like programming with cmsis.
I hope unicore-mx to be based on abstraction because cross-family development with libopencm3 is a nightmare….
(e.g. some functions of F1 family are moved from one subsystem to another in F4, for example, adc prescaler, is on rcc in F1 and on adc in F4, the naming of functions in libopencm3 start with the subsytem, as a result the same function is rcc_set_adcpre(value) in F1 and adc_set_clk_prescale(value) in F4, they dont have difference only in prefix but also in description… total unconsistency…)
It is sad, if and when the naming conventions are not matching due to lack of higher level planning. In practice, perhaps MBED is the only viable solution for HAL and family consistency.
Personally, I am happy with LOCM3 solution to have consistency only within the families. The fact that the hardware internals are not totally hidden makes LOCM3 a clean and mean fighting machine suitable for many resource critical applications.
I’m so allergic for bloatware that my head could explode if spending any extended time with it.
Cheers, Ollie
While there are differences between families in register level, we need a thin layer to unify as much as possible these differences. The typical example of setting the adc prescaler shows the problem. I think that opencm3 is in right direction but a lot of work must be done yet.
In the arduino_opencm3 core we try to keep the core unified and to move any differences in stm32/xxx_arh files. I thought that these cases would be few but it seems to be the rule…. I hope unicore-mx will try to solve some of these problems.
We are happy to announce our unfiied API proposal and roadmap here: https://github.com/insane-adding-machin … /issues/18
We welcome discussion about our proposal as well as any ideas/thoughts/comments!
Looking forward to all feedback on our plan!
brabo.
We are happy to announce our unfiied API proposal and roadmap here: https://github.com/insane-adding-machin … /issues/18
We welcome discussion about our proposal as well as any ideas/thoughts/comments!
Looking forward to all feedback on our plan!
brabo.
We also feel a hard break is the way to go at this moment. The library is pretty fragmented and inconsistent at this point, so almost any change will end up breaking things for user code. It is also making it hard on contributors to add something to the library, and is especially hard for new developers to get involved.
Our roadmap directly quoted from our RFC is:
– Announce proposal and roadmap, solicit community response on github
– 3-4 weeks: propose the unified API, solicit community response
– 7-8 weeks: end RFC phase, start implementation in seperate branch and freeze master
– 8-12 weeks: finalise unified lib and make it master
We tried to make both a realistical timeline for this move and allow time for feedback, as well as it being speedy. We hope the actual implementation phase can be shorter than 4 weeks, but we may hit unforeseen issues (they have a nasty habbit of doing that :p).
We are at this moment already expanding hardware support, but to make that as painless as possible first we need a clear defined API, and consistency. We hope we will end up being able to support all the Cortex-M families that make sense to be in this library, but it is a seperate schedule from unfiying the API.
Hope this answers your question to satisfaction ![]()
brabo.